Network Design in Stable Diffusion
StabilityAI has recently open sourced a series of foundational models for image generation, called Stable Diffusion. Although we know these models are based on latent diffusion, there are few reports mention their detailed designs. To facilitate better understanding and potential future improvement, this blog provide some information about the designs of Unet and VAE, which are key components of the magic generation.
Unet
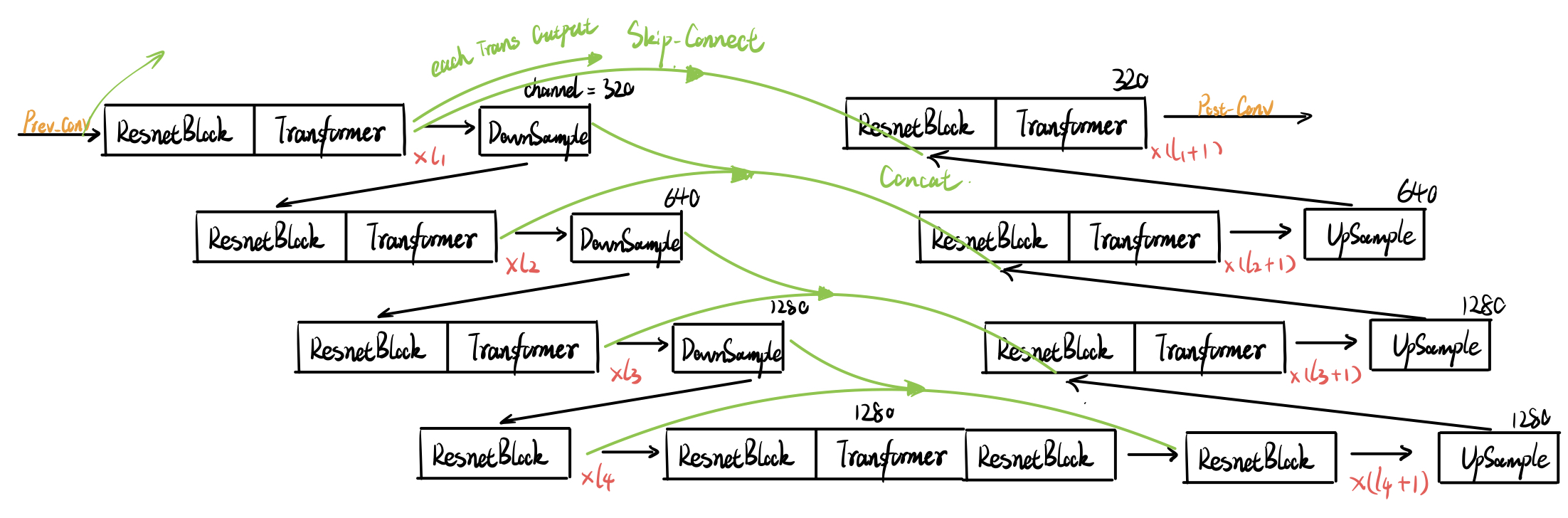
As in Fig.1, this Unet is consist of alternating convolution layers and transformer layers, which is the modern design to provide stronger representation than pure-conv or pure-transformer in the vision field. In SD1.x & SD2.x, $l_1=l_2=l_3=l_4=2$.
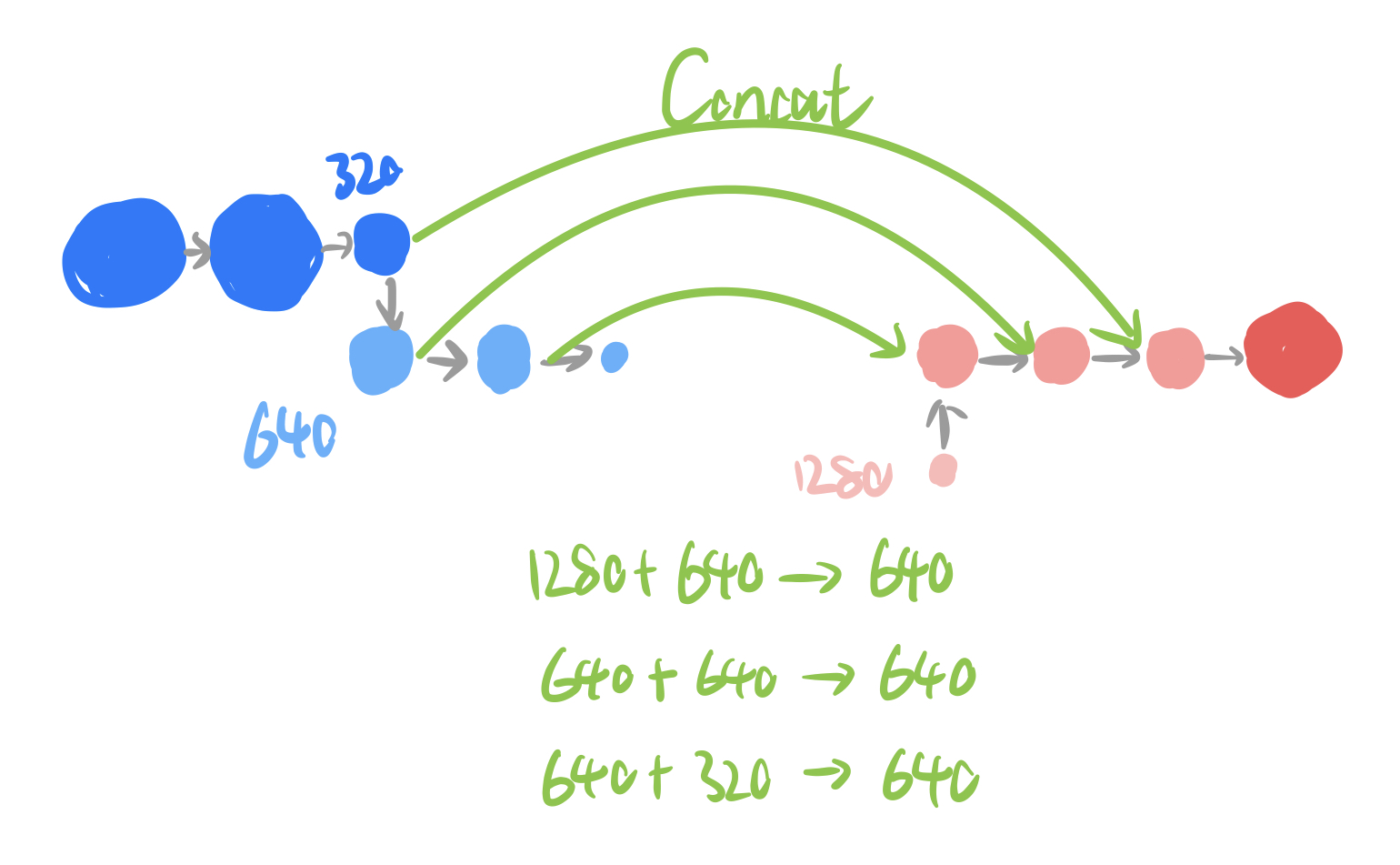
The skip-connection of this Unet is very dense, where the output from each transformer in encoder (downsample side) will be transmitted and concatenated with the corresponding decoder layer’s input as in Fig. 2.
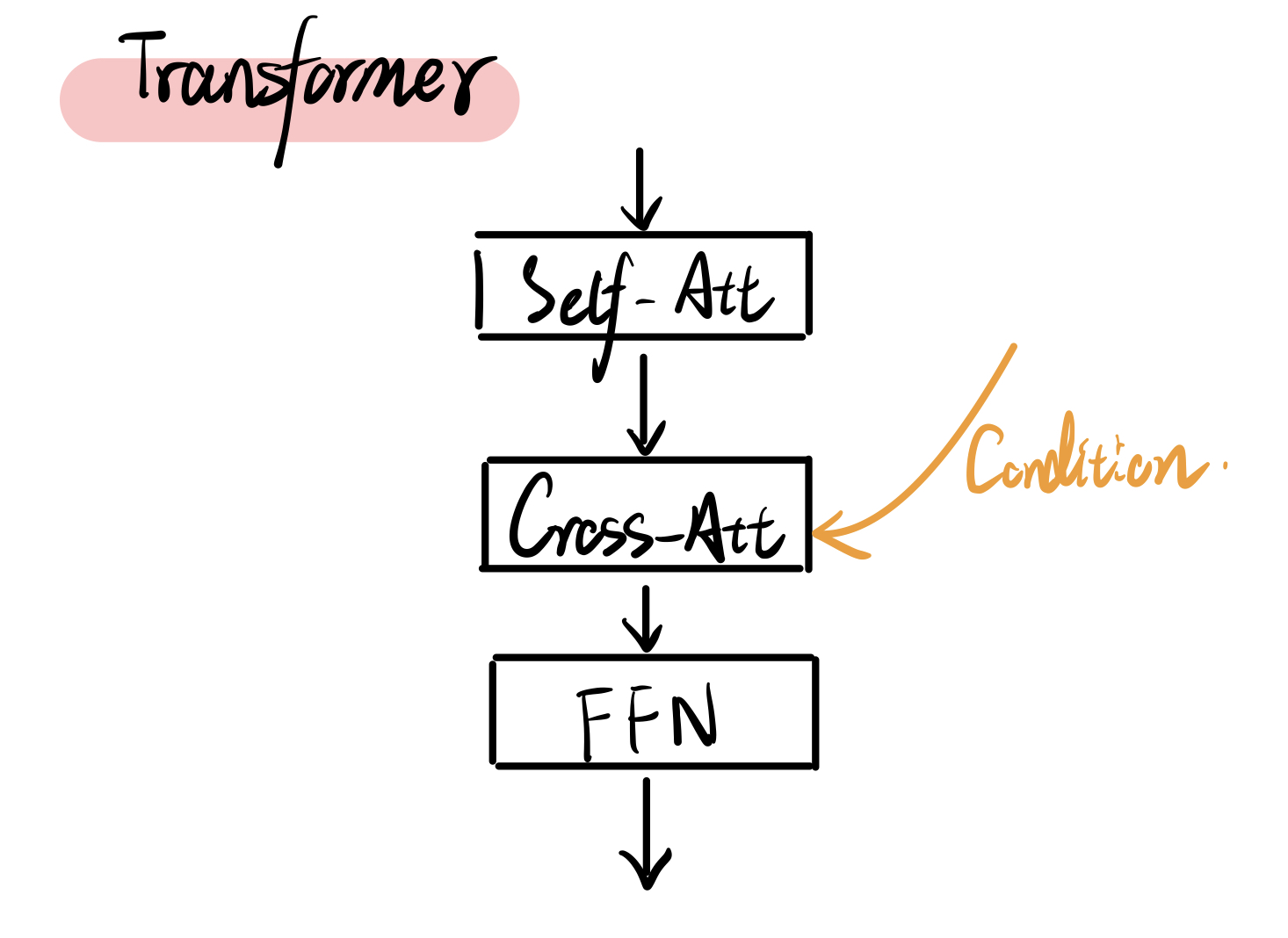
In the cross-attention, it is worth noting that the feature from extra condition is regarded as key $K$ and value $V$, and the feature from latent is regarded as query $Q$. This setting follow s the classical decoder design in the autoregressive language transformer. At the same time, it is reasonable to use rich information as the base to generate.

The SiLU activation has been widely utilized in this unet, it can provide better capability for nonlinear modeling.
$$ \text{SiLU}(z)=z*\text{sigmoid}(z) $$
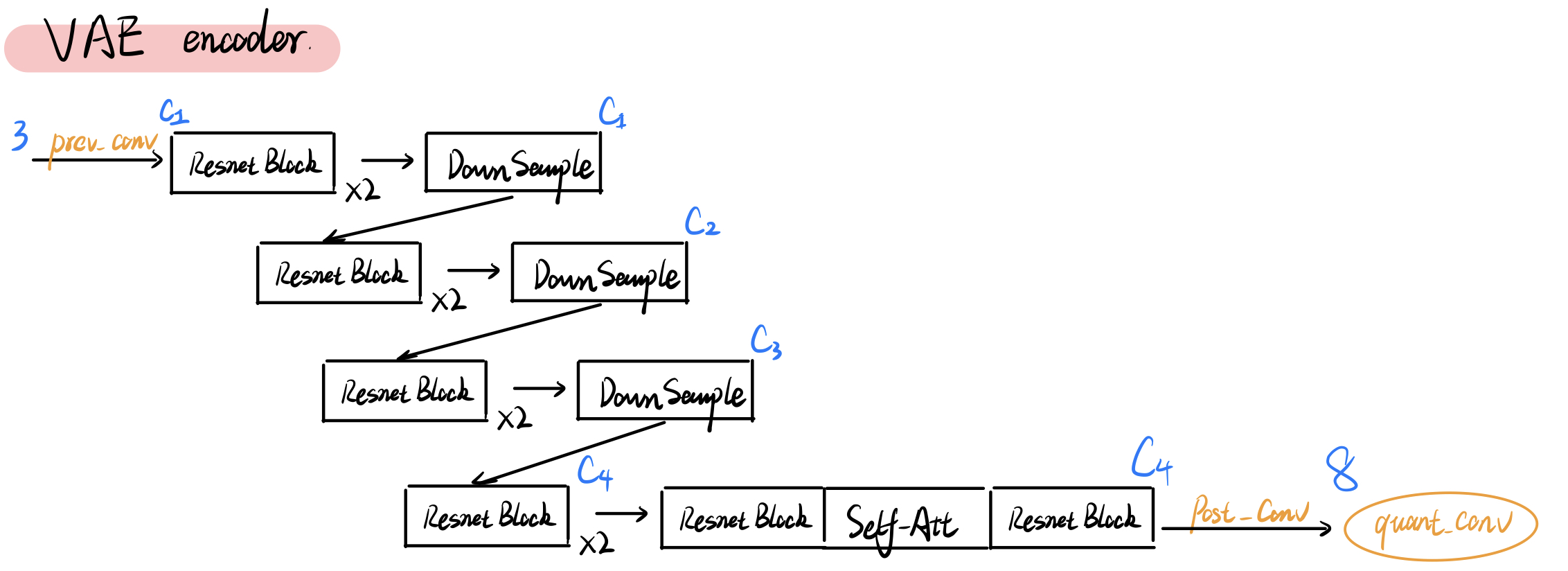
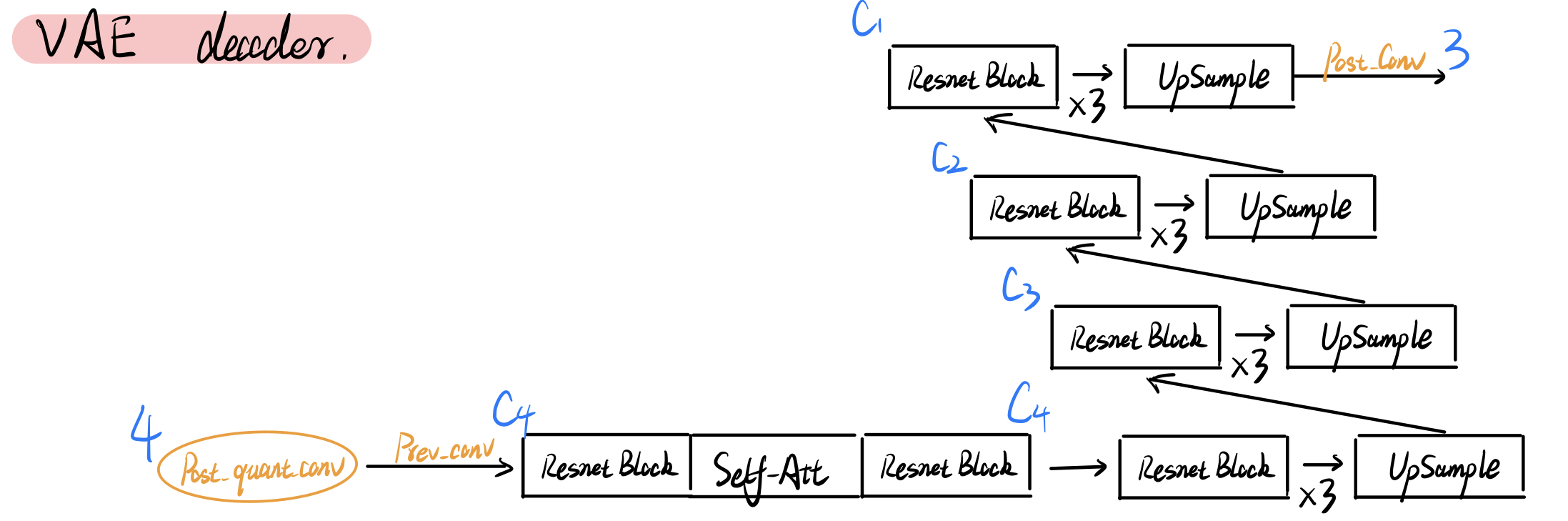
VAE
The KL-regularized VAE is almost composed of convolutions, expect for one self-attention layer at the bottom. SD1.x and SD2.x have the same structure of VAE (the numbers of channel $c_1,c_2,c_3,c_4=128,256,512,512$), but they don’t have the same weight (SD2’s VAE might be fine-tuned for higher resolution $768\times 768$).
Tiled Processing
In inference, VAE decoding often occupies a lot of memory.
In the tiled mode, the VAE will split the input tensor into tiles to compute encoding in several steps, feed the fully concatenated latent into U-net for denoising, spilt the result again, and finally decode these tiles by a tiled VAE decoder.
This is useful to keep memory use constant regardless of image size, but the end result of tiled encoding is different from non-tiled encoding. To avoid tiling artifacts, the tiles overlap and are blended together to form a smooth output.