Generating Images Like Texts
Can we generate images in the same way as autoregressive language model?
Although this sounds simpler than diffusion models, we still need to deal with many computational cost problems. But don’t worry too much, there are serval brilliant methods to try to make this idea more competitive.
Taming Transformer
-> Patrick Esser, et al. CVPR 2021
The key challenge of autoregressive generation is how to solve the quadratically increasing cost of image sequences that are much longer than texts. For this sake, the Taming Transformer is designed as a two-stage approach including a VQGAN and an Autoregressive Transformer.
1.1 VQ-GAN
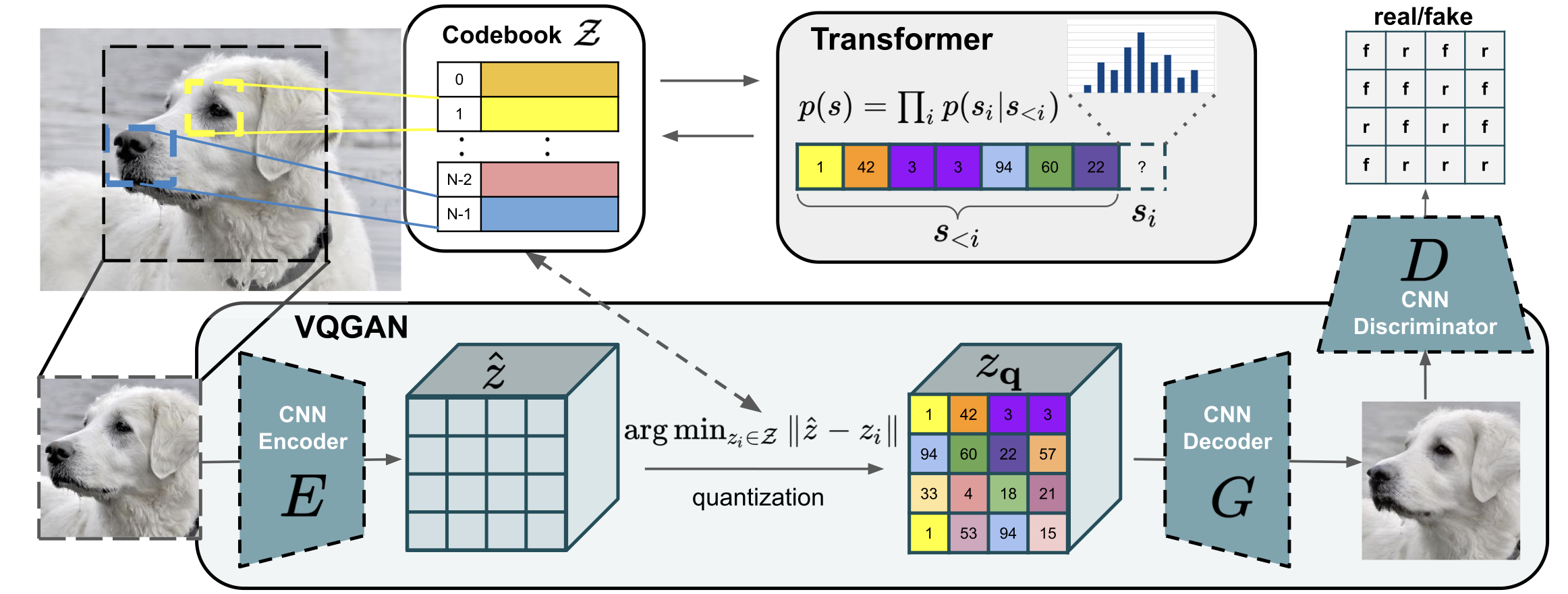
Vector quantization is a brilliant idea to provide the compression and discrete representation for images (like a image tokenizer). Inspired by that, VQ-GAN realizes more effective representation with patchGAN, compressing an image into a learnable space (codebook). More precisely, any image $x\in R^{H\times W\times 3}$ can be represented by a discrete vector $s \in R^{h×w}$ (an index set of the closest codebook entries).
The training objective for finding the optimal compression model can be expressed as:
$$ \begin{align} &L_{VQ}=L_{perceptual}+||sg(E(x))-z_q||^2_2+\beta||sg(z_q)-E(x)||^2_2 \\ &L_{GAN}=\log{D(x)}+\log{(1-D(\hat{x}))} \\ &\arg{\min_{E,G,Z}\max_{D}}\ \mathbb{E}\lbrack L_{VQ}(E,G,Z)+\lambda L_{GAN}(E,G,Z,D)\rbrack \end{align} $$
where the adaptive weight $\lambda=\nabla_{G_L}[L_{rec}]/(\nabla_{G_L}[L_{GAN}]+10^{−6})$ tends to focus on the smaller one of $L_{rec}$ and $L_{GAN}$.
1.2 Autoregression
For the autoregressive transformer, it can be implemented by the “decoder-only” structure and the casual self-attention mask. And we can directly maximize the log-likelihood of the data representations as:
$$ L_{Transformer} = \mathbb{E}[-\log(\Pi_i{p(s_i|s_{<i})})] $$

When generating images in the megapixel regime (>256^2), that transformer will adopt the local attention in a sliding-window manner for efficiency. Since transformer is a kind of network without inductive bias, we need the spatial conditioning information or the training dataset with spatial invariance to ensure such local strategy work well.
Parti
-> Jiahui Yu, et al. arXiv 2022
Parti (Pathways Autoregressive Text-to-Image) shows that above two-stage autoregressive method is able to realize high-fidelity generation for text-to-image with additional fine-tuning and upsampling.
2.1 ViT-VQGAN
They first train a stronger ViT-VQGAN-Small encoder (30M) as a image tokenizer on their training data, which achieves 4x downsampling (i.e., $256\to 32$) and learns 8192 image token classes for the codebook.
2.2 Text-to-Image
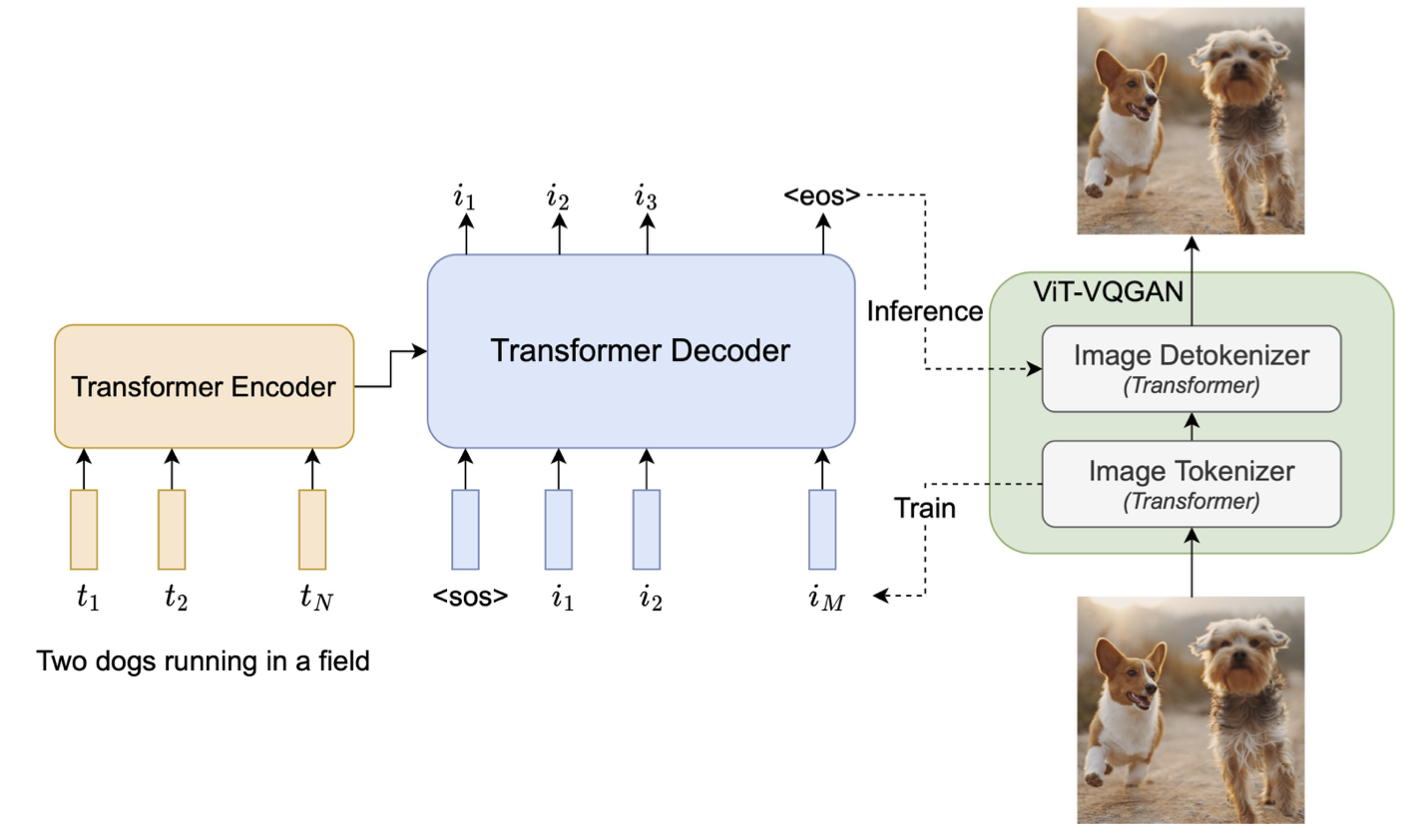
The text-to-image model is based on a classical encoder-decoder architecture in multi-modal tasks.

They build a SentencePiece model as the text encoder which provides text tokens of length 128. This text encoder is first pretrain on two datasets: the C4 datasets with BERT loss, and their image-text datasets with contrastive loss.
After pretraining, they continue training both encoder and decoder for text-to-image generation with softmax cross-entropy loss. Nothing that the decoder uses conv-shaped masked sparse attention (like the sliding window in Taming Transformer).
The ability of text encoder after pretraining performs comparably to BERT, but degrades after the full encoder-decoder training, which indicates the difference between language representation and image-grounded language representation.
Classifier-free guidance has been adopted to great effect for Parti. During inference, tokens are sampled from a linear combination of logits sampled from an unconditional model and a conditional model on a text prompt.
2.3 Fine-tune & Super-Resolution
After two-stage training, they freeze the image tokenizer and codebook, and fine-tune a larger-size image detokenizer (600M) to further improve visual acuity.
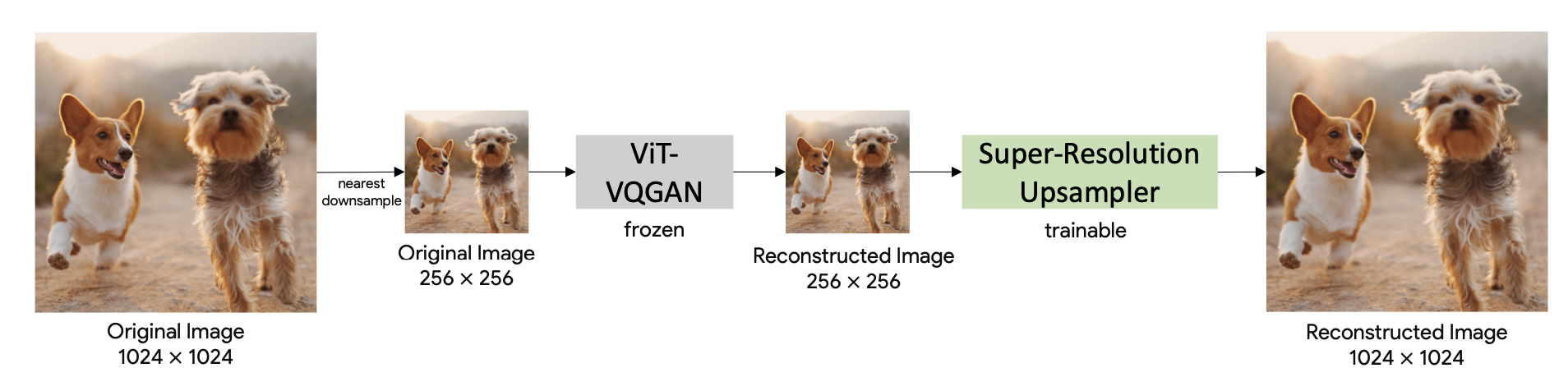
Moreover, they employ a simple super-resolution network (15M~30M) on top of the image detokenizer. This SR-network is based on WDSR and trained with the same losses of ViT-VQGAN (perceptual loss, StyleGAN loss and l2 loss). It has about 15M parameters for 2x upsampling and 30M parameters for 4x upsampling.
Muse
-> Huiwen Chang, et al. arXiv 2023
Although above solutions alleviate high training cost to some extent, the autoregressive paradigm still slows down inference significantly. Can we adopt parallel iteration instead of one by one? Muse give that answer which employs a random masking strategy (like MLM in NLP) to facilitate predicting multiple tokens at once.
3.1 Frozen LLM as Text Encoder
Recent works show that the conceptual representations learned by LLMs are roughly linearly mappable to those learned by models trained on vision tasks. Fueled by these observations, Muse adopts frozen T5-XXL as the text encoder and tries to map those rich visual and semantic concepts in the LLM embeddings to the generated images. These embedding vectors are linearly projected to the hidden size of later Transformer models (base and super-res).
3.2 Base Model
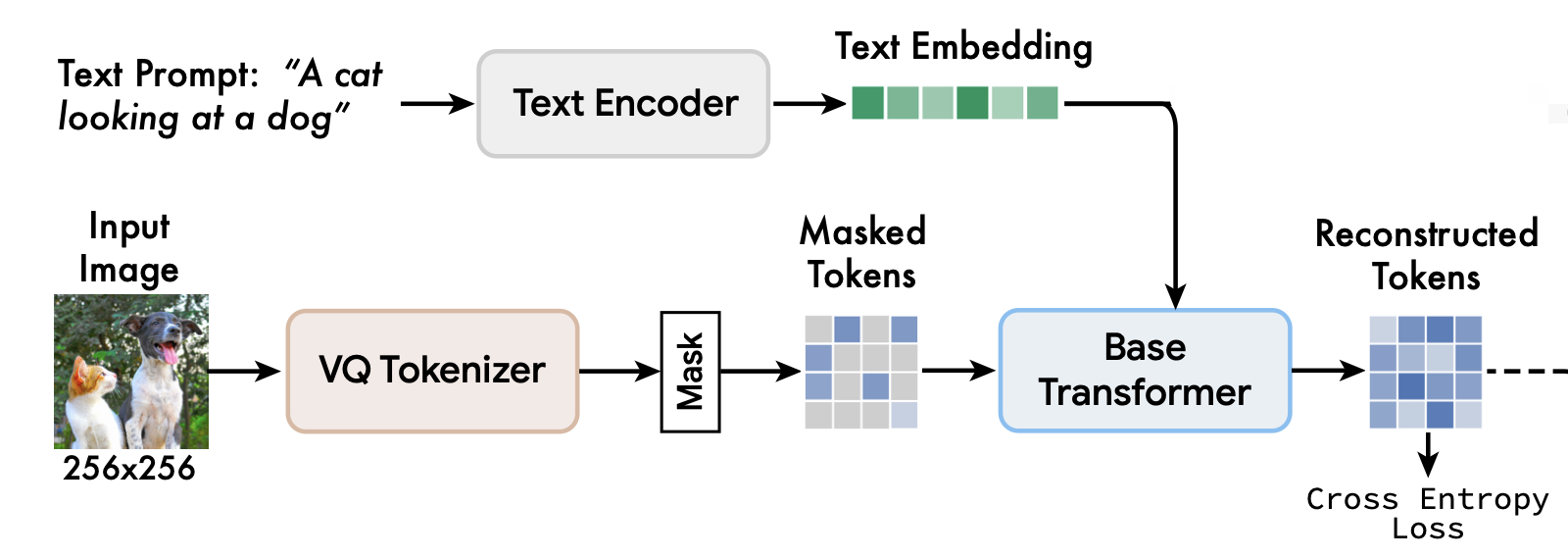
Muse’s base model has the same encoder-decoder architecture as Parti, but it employs a random masking strategy to ensure learning more expressive and robust.
They leave all the text embeddings unmasked and randomly mask a varying fraction of image tokens and replace them with a special [MASK] token. The masking rate is a variable based on a cosine scheduling $r\sim p(r)=\frac{2}{\pi} (1 − r^2)^{-1/2}$, where the bias towards higher masking rates makes the prediction problem harder.
Noting that this masking functions on input rather than attention layers.
In this way, the base model is trained to predict all masked tokens at once.
3.3 Super-Resolution Model
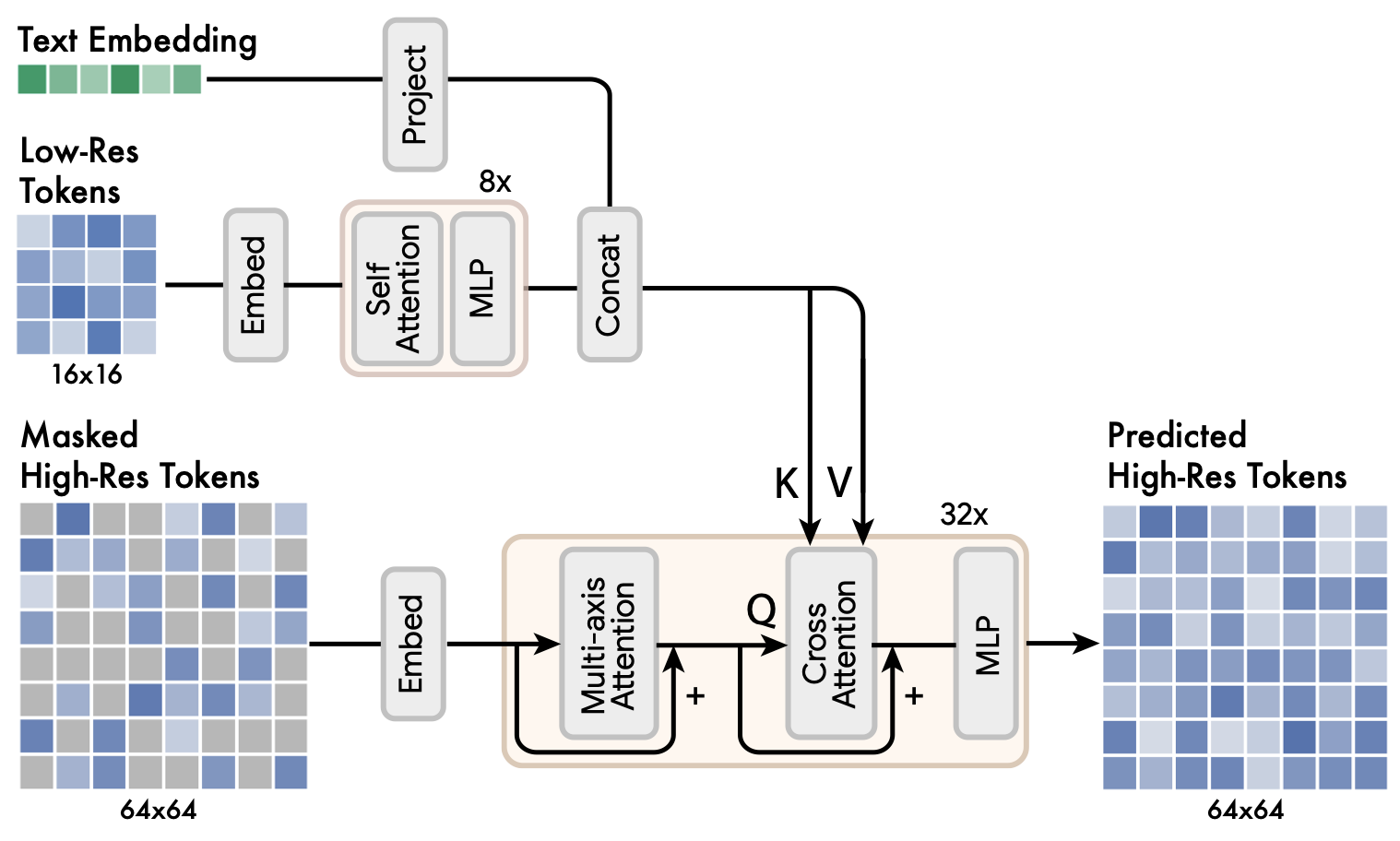
For the high-resolution generation, the authors found that directly predicting $512\times 512$ resolution leads the model to focus on low-level details over large-scale semantics. To this end, they trained another decoder to predict masked tokens in higher resolution with the help of low-res conditioning and text conditioning.
3.4 Fine-tune
Following the Parti model, Muse increases the capacity of the VQGAN decoder by the addition of more residual layers and channels, and then fine-tune the new decoder layers while other modules frozen.
3.5 Iterative Parallel Decoding
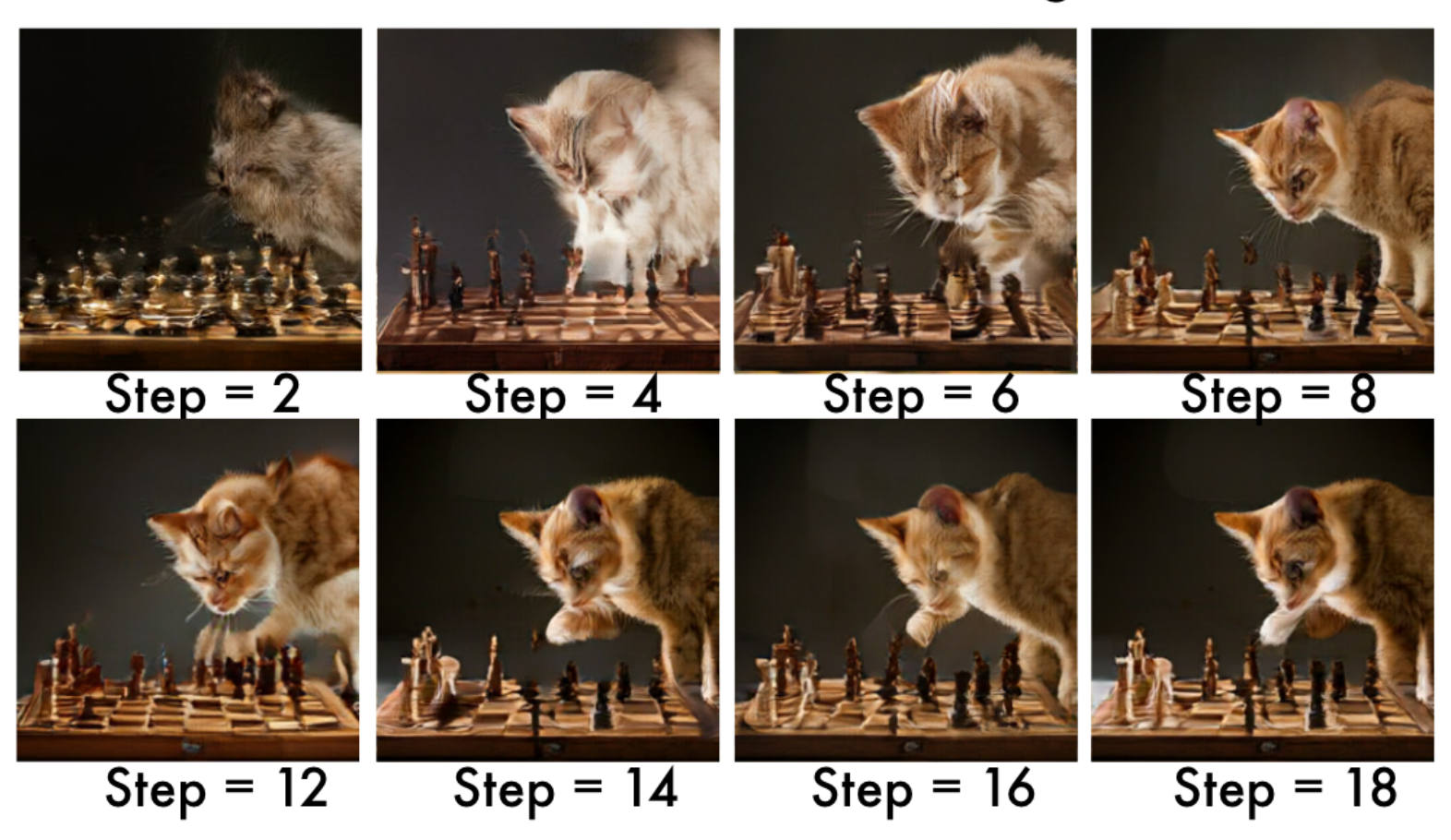
The above masked learning support us to decode multiple tokens at each step, so this inference is called as iterative parallel decoding. Based on a cosine schedule, we predict all masked tokens at each step, and choose a fraction of the highest confidence tokens as unmasked, and continue next step to predict remaining masked tokens.

Using this procedure, Muse is able to perform high-fidelity inference using only 24 steps in base model and 8 steps in super-resolution model, and is significantly faster than competing diffusion or other autoregressive models.