Learning the Multi-modal Feature Space
In multi-modal tasks, one of the key challenges is the alignment between feature spaces of different modals. CLIP is representative of this type of work. Although its motivation is to learn a transferable visual model (like BERT) for downstream vision tasks, CLIP has brought a lot of inspirations for multi-modal tasks. Therefore, I prefer to describe CLIP and variants as how to learn a better multi-modal feature space.
CLIP
-> Alec Radford, et al. NeuraIPS 2021
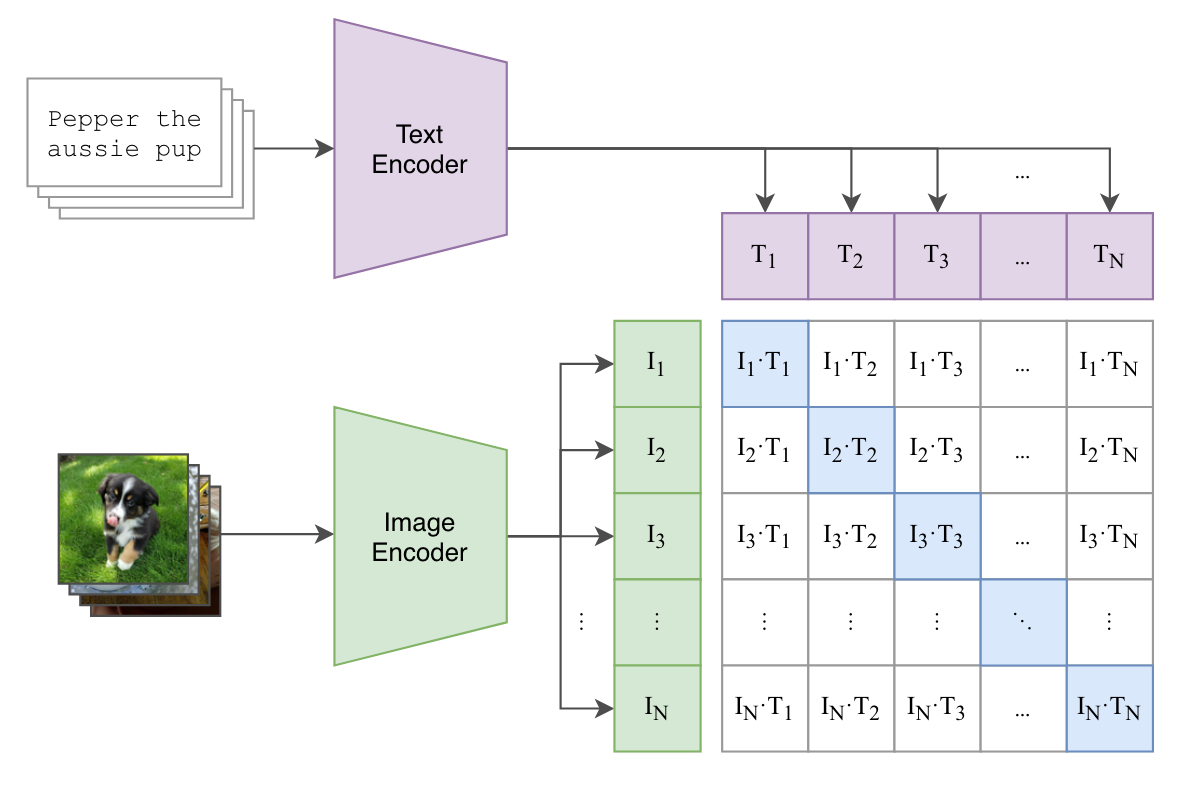
1.1 Bag-of-words encoding
In the text encoder, the output at last [EOS] token are used as the feature representation of the text (i.e. $[N,L]\to[N,L,D]\to[N,D]$). The authors refer to this process as “Bag-of-words Encoding” where the text of arbitrary length can be encoded into a D-dimensional vector.
In Stable Diffusion, CLIP’s text encoder is used to provide crucial text feature. People often take full-sequence features (skip last 1 or 2 layers) from CLIP’s text encoder into the cross-attention to realize a “word-by-word instruction”. But indeed, if you take only the feature at last [EOS] token as the instruction, the results will be fine due to its globality.
1.2 Contrastive learning
The contrastive learning is implemented by optimizing a symmetric cross entropy loss over the cosine similarity score. We say that an image-text pair is matched if the cosine similarity between their embeddings is high enough.
In this paper, they set a learnable temperature parameter $e^t$ to scale the similarities, but didn’t explain much. I speculate such exponentiation can make learning more sensitive (imagine that steep curve) than a pure scalar.
BTW, the authors separate out l2_normalize() and refer to np.dot() as the cosine similarity, which is of course equivalent but might be confusing.
BLIP
-> Junnan Li, et al. ICML 2022
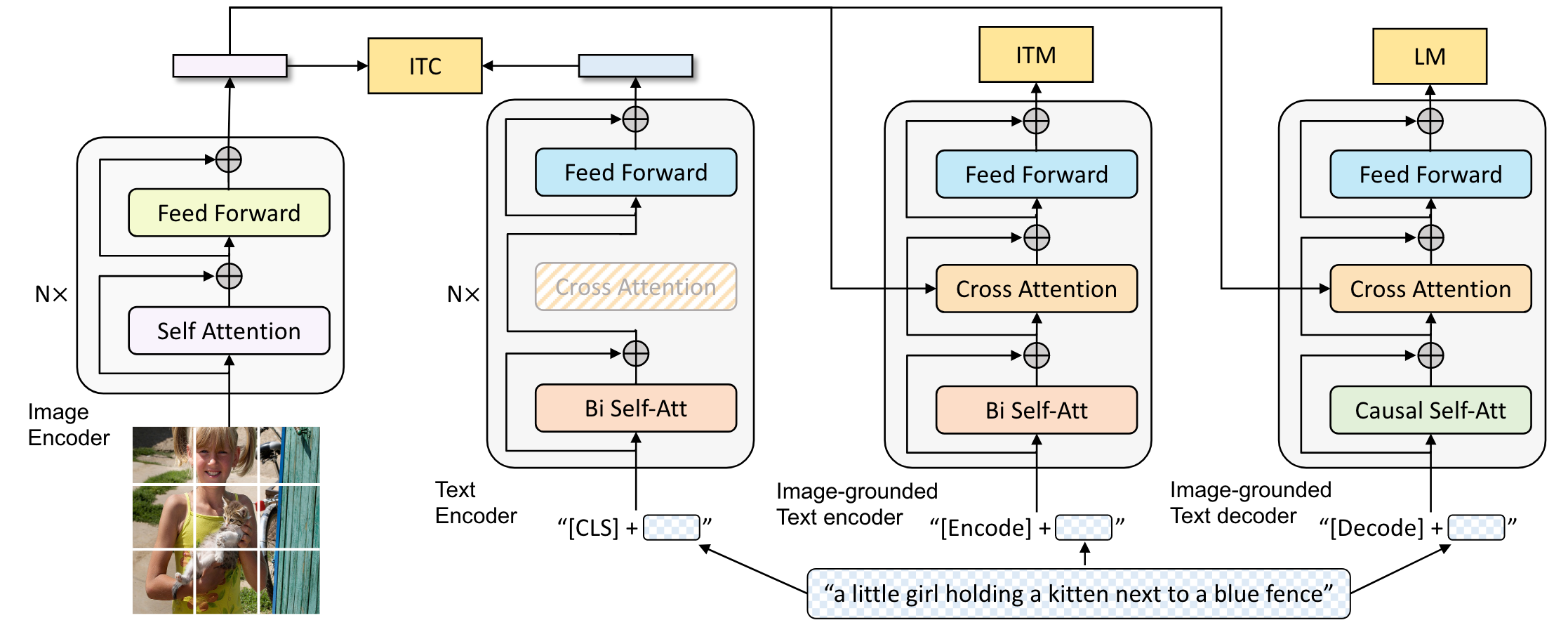
In addition to the contrastive learning, BLIP introduces two more vision-language objectives: image-text matching and image-conditioned language modeling. Such multimodal mixture of encoder-decoder model is jointly trained with three objectives, enabling a wider range of downstream tasks.
2.1 Coarse-grained alignment
Similar to CLIP, BLIP includes the image-text contrastive learning by two unimodal encoders. We can think of such alignment is coarse-grained, since the interaction between the features from two modalities occurs only in the last shallow linear network.
A few differences from CLIP are listed below:
- The global feature of the whole text is allocated at the first [CLS] token instead of the [EOS].
- BLIP’s text encoder and image encoder is initialized from BERT-base and ViT (pre-trained on ImageNet), instead of training from scratch. (CLIP’s networks are heavily modified and scaled, so there are certainly no suitable pre-trained baselines for initialization.)
2.2 Fine-grained alignment
The image-grounded (conditioned) text encoder aims to learn image-text multimodal representation with dense cross-attention layer, which can capture the fine-grained alignment. The objective is a binary classification task to predict whether an image-text pair is matched or not.
Noting that here they adopt the hard negative mining strategy, where those negatives pairs with higher contrastive similarity in a batch will be more likely to be chosen to compute the 0-1 loss. It makes sense because some unmatched pairs may have quite high cosine scores. Such filtering strategy is obviously another sense of fine-grained.
2.3 Language modeling
Altering to the masked self-attention can preserve the ability of language modeling with a new auxiliary objective, and is the future work as mentioned in CLIP. Now BLIP realizes this thing with the image-grounded text decoder.
This decoder is inherited from the image-grounded text encoder, where bi-directional SAs are replaced with causal SAs (i.e. triangle) just like in the regular text decoder. Correspondingly, it optimizes a cross entropy loss which trains the model to maximize the likelihood of the text in an autoregressive manner. And the text decoder share all parameters with text encoder except for the SA layers, since the remaining layers serve a similar function.
Preserving the ability of LM enforce the image feature to capture all the information about the text, therefore make it easy to transfer to those vision-language generation tasks, such as Image Captioning, Visual Question Answering, and etc. But this LM objective also makes the learned feature more “text-like”, whether from the text encoder, text decoder, or even image encoder.
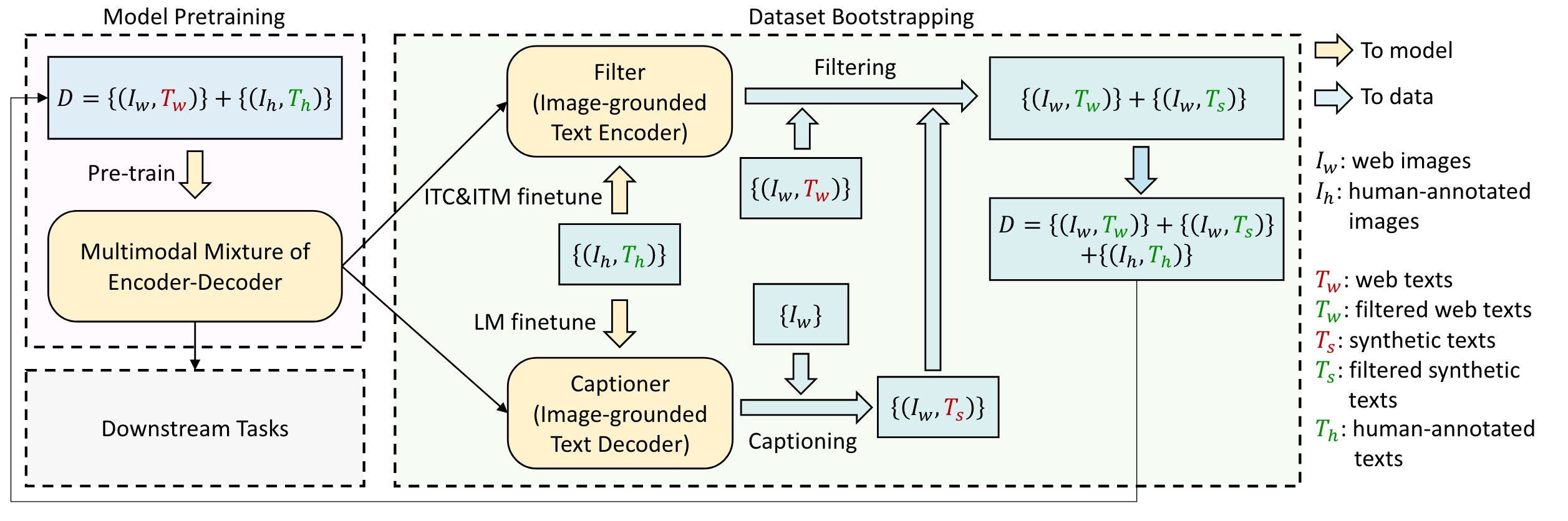
2.4 Dataset bootstrapping
BLIP-2
-> Junnan Li, et al. arXiv 2023
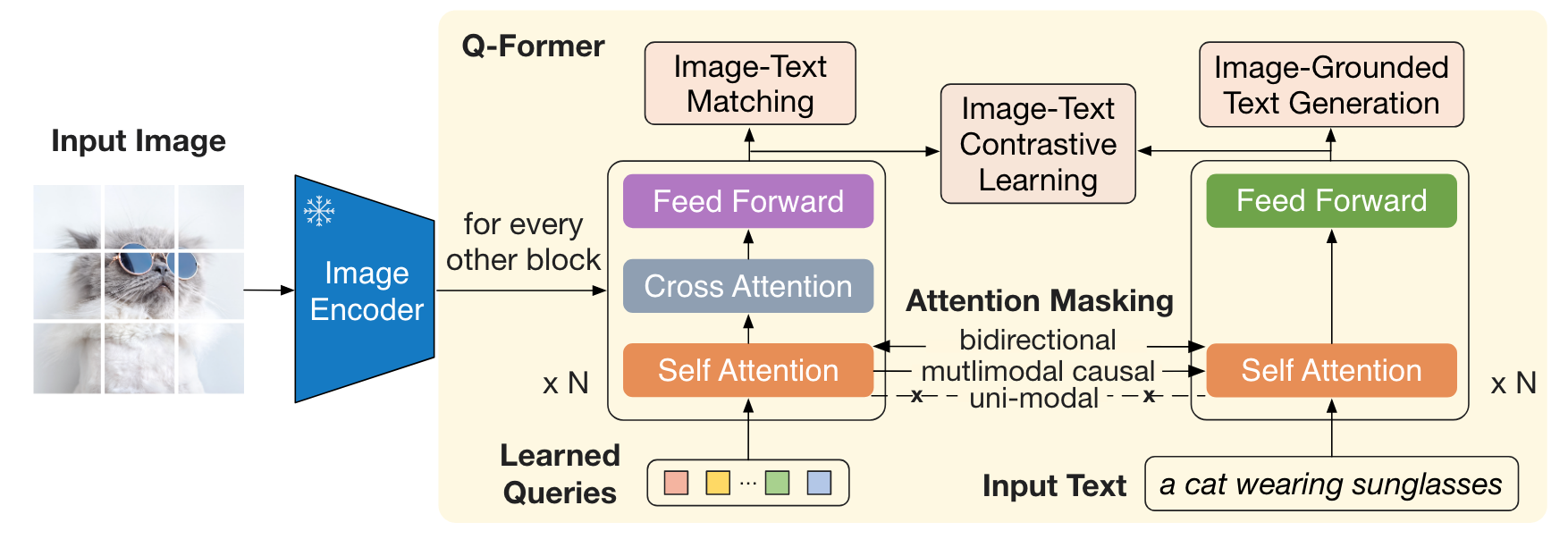
BLIP-2 consists of (1) an image transformer that interacts with the frozen image encoder for visual feature extraction, (2) a text transformer that can function as both a text encoder and a text decoder. These two transformers share the same SA layers.
3.1 Learnable queries
A set number of learnable queries is created as input to the image transformer. Instead of taking image patches as input, allocating learnable queries can output the smaller-length $L=32$ features independent of image resolution (since the encoder/decoder-only model outputs the same length sequence as input). The output embeddings from these queries will be forced to extract visual features that capture all the information about the text, by three objectives. Due to such query’s importance, BLIP-2’s network is also known as the Q-Former.
3.2 Shared self-attention
We have observed that BLIP-1’s sub-networks have many common points in architectures and even in weights. So why not merge them as possible? and how?
The brilliance of BLIP-2 is that they employ different SA masking strategies for different objective to restrict the interaction between the vision token and text token, so two branches in the Q-Former can share the same SA layers.
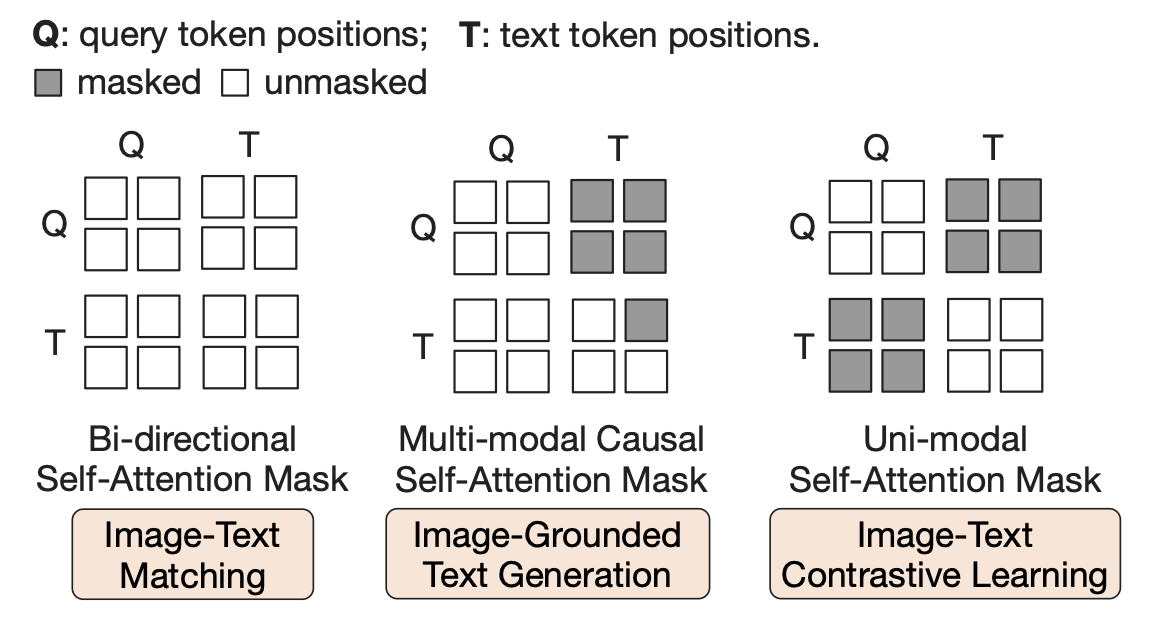
Although the masking strategies and the joint-training for three objectives sounds very straightforward and reasonable, there are a lot of unclear details waiting to be revealed in the source code.
For the contrastive learning, the query and text will be passed into Q-Former, respectively. Noting that the key&value of SA layers in the image transformer will be cached for later use.
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
use_cache=True,
return_dict=True,
)
text_output = self.Qformer.bert(
text_tokens.input_ids,
attention_mask=text_tokens.attention_mask,
return_dict=True,
)
For the image-text matching, the query will be concatenated with the text and passed into Q-Former. All queries and texts can attend to each other.
output_itm = self.Qformer.bert(
text_ids_all,
query_embeds=query_tokens_itm,
attention_mask=attention_mask_all,
encoder_hidden_states=image_embeds_all,
encoder_attention_mask=image_atts_all,
return_dict=True,
)
For the language modeling, there are only the text (first token is replaced by [DEC]) as input to the Q-Former. As the visual instruction, the previous key&value caches (with pure visual information) will be concatenated with the current key&value (from the texts), and then passed to the SA layers with a multimodal causal mask.
lm_output = self.Qformer(
decoder_input_ids,
attention_mask=attention_mask,
past_key_values=query_output.past_key_values,
return_dict=True,
labels=labels,
)
Compared to BLIP-1, the shared SAs of BLIP2 make the output query embeddings more “text-like” inevitably, so the image encoder should be frozen to counteract such imbalance.
3.3 Bootstrap LLM
Benefit from the LM objective, the output query embedding contains rich image and text features. So them can function as soft visual prompts to LLM by a simple linear projection.
